-
[강화학습] flexSim과 강화학습 그동안의 뻘짓 기록CS/ML&DL 2022. 10. 11. 23:35
※ 의식의 흐름으로 작성된 글이니 주의
기획업무 그 중에서도 DT관련 업무를 맡다보면, 다음과 같은 딜레마에 빠지게 되는 듯 하다.
무언가 새로운걸 해야한다는 압박과, 한편으로는 과연 이게 되는 것인가에 대한 의문 사이가 왔다갔다 한다.
두달짜리 째간이 신입이지만, 그래도 나 정도전 석사출신이 아니던가.
주 메인업무인 시뮬레이션 업무에 데이터분석을 담아보고자 했다. 그러던 중 FlexSim SW에 강화학습 기능이 탑재되어있단 것을 발견했다.
https://docs.flexsim.com/en/22.1/ModelLogic/ReinforcementLearning/Training/Training.html
Reinforcement Learning Training
© 1993 - 2022 FlexSim Software Products, Inc. All Rights Reserved. FlexSim®, FlexSim Healthcare™, Problem Solved.®, the FlexSim logo, the FlexSim X-mark, and the FlexSim Healthcare logo with stylized Caduceus mark are trademarks of FlexSim Software Pr
docs.flexsim.com
요약을 하자면,
소스(물건이 튀어나오는 곳) -> 큐 (대기장소) -> 프로세서(뭔가 처리하는 설비) -> 싱크(실질적으로 처리되었음)
이런 로직에서, 강화학습을 통해 큐 내부에 서로다른 item이 섞여있을때
어떤 item을 먼저 processor에 보내야 가장 프로세서의 처리량이 좋은지를 보이는 인공지능 모델을 만드는 과정이다.
처음에는 flexsim이라는 SW와 강화학습이라는 아이템을 보고 무작정 달려들었지만, 이내 다음과 같은 질문에서 막혀버렸다.
Q. 인공지능은 현실의 문제를 해결하기 위한 도구 아닌가?
그런데 시뮬레이션 내부 요소를 똑똑하게 해 봐야 뭐가 좋은건가?
내부 요소가 똑똑해지는게 외부 요소에 어떠한 영향을 미치는건가???
그렇다. 강화학습으로 유명한 알파고, 그리고 비교적 최신 나온 스타크래프트를 정복한 알파스타 들은 사실
게임 세계 내부에서 가장 강력해지면 된다, "통제된 환경"에서 가장 강력한 모델을 만들고 이를 자랑하기에는
가상세계나 게임이 강화학습에게 가장 적합하다.
외부 요소에 직접적인 영향이 없으면 아무짝에 쓸모 없는 작품이 되어버린다.
특히 나같은 회사원에게 이러한 접근은 치명적이다. 직접적인 실적(몇명분의 업무량을 줄였다거나...)이 필요하기 때문이다.
그런데 나와 같은 의문점을 갖는 사람들이 꽤 많았나보다.
Q2. 시뮬레이션 속 모델을 강화학습 하는 목적이 뭐야?
거기에 대해 Flexsim 관계자가 이러한 답변을 내놓는다.
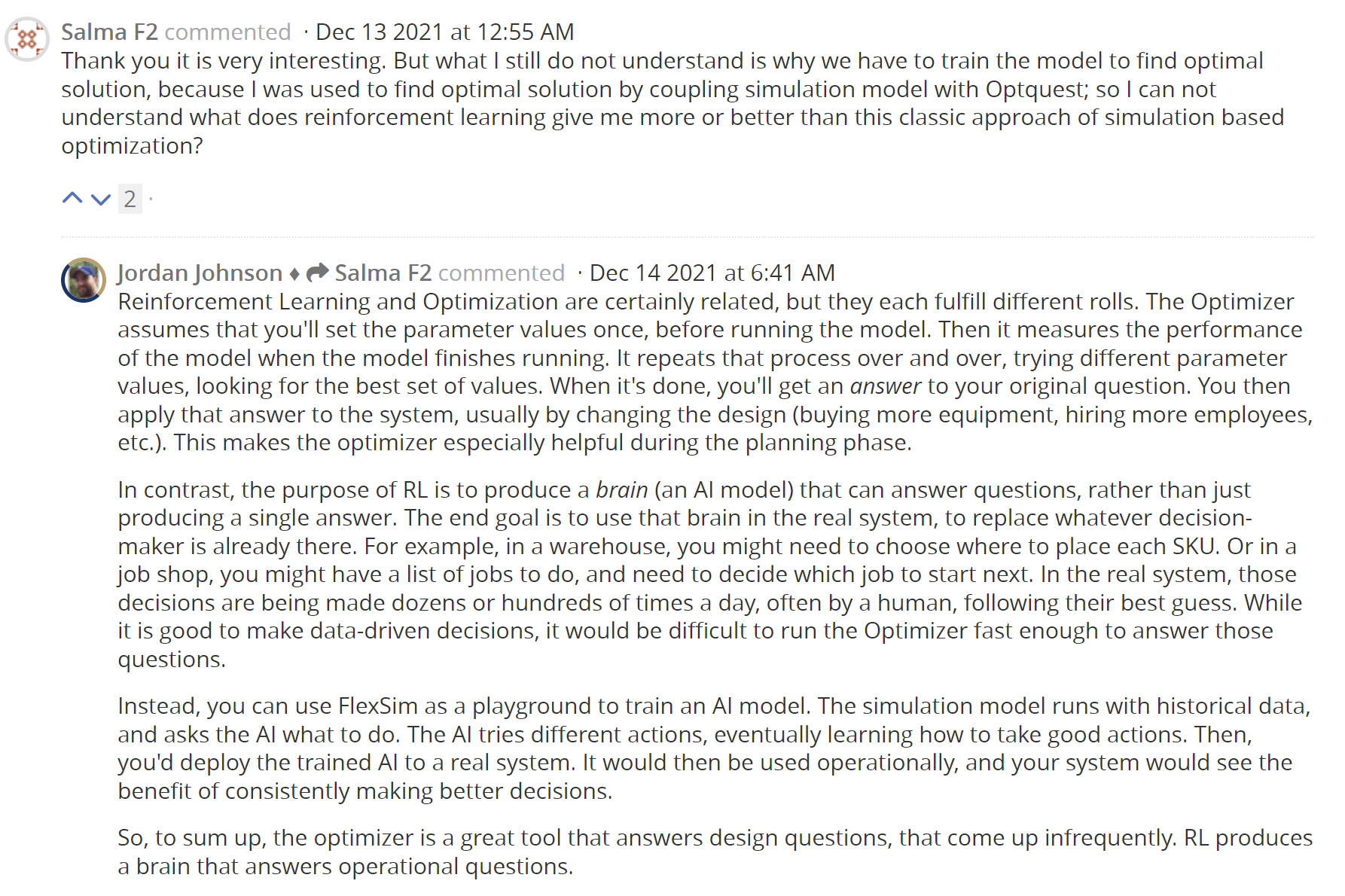
============================
번역 :
강화 학습과 최적화는 확실히 관련이 있지만, 각각 다른 역할을 수행한다. Optimizer는 모형을 실행하기 전에 모수 값을 한 번 설정한다고 가정합니다. 그런 다음 모델 실행이 완료되면 모델의 성능을 측정합니다. 이 프로세스는 다른 매개 변수 값을 시도하고 최적의 값 집합을 찾는 과정을 반복하여 수행합니다. 작업이 완료되면 원래 질문에 대한 답을 얻을 수 있습니다. 그런 다음 일반적으로 설계를 변경하여(장비 구입, 직원 채용 등) 해당 답변을 시스템에 적용합니다. 따라서 최적화 도구는 계획 단계에서 특히 유용합니다.
이에 비해 RL의 목적은 단순히 하나의 답을 도출하는 것이 아니라 질문에 답할 수 있는 두뇌(AI 모델)를 생산하는 것이다. 최종 목표는 그 뇌를 실제 시스템에서 사용하는 것입니다. 이미 존재하는 의사 결정자를 대체하기 위해서죠. 예를 들어 창고에서 각 SKU를 배치할 위치를 선택해야 하거나 작업장에서 수행할 작업 목록이 있을 수 있으며 다음에 시작할 작업을 결정해야 합니다. 실제 시스템에서, 그러한 결정은 하루에 수십 번 또는 수백 번, 종종 인간이 최선의 추측에 따라 내려지고 있습니다. 데이터 중심 의사 결정을 내리는 것은 좋지만, 이러한 질문에 답할 수 있을 만큼 Optimizer를 빠르게 실행하는 것은 어려울 것이다.(SKU : stock keeping unit)
대신 FlexSim을 AI 모델을 훈련시키는 놀이터로 사용할 수 있다. 시뮬레이션 모델은 과거 데이터와 함께 실행되며, AI에게 무엇을 해야 할지 묻는다. 인공지능은 다른 행동을 시도하고, 결국 좋은 행동을 취하는 방법을 배운다. 그런 다음, 당신은 훈련된 인공지능을 실제 시스템에 배치할 것이다. 그런 다음 운영상 사용되므로 시스템이 지속적으로 더 나은 결정을 내릴 수 있는 이점을 볼 수 있습니다.
요약하자면, 옵티마이저는 드물게 나타나는 디자인 질문에 답하는 훌륭한 도구입니다. RL은 작동 질문에 답하는 뇌를 생산한다.==========================
1. Optimizer와 RL은 다르다. Optimizer는 최적의 값 집합을 찾는 과정을 반복수행
2. RL은 반복수행 속에서 훈련된(준비된) 모델이 새로운 환경이 들어올 때 대리 의사결정을 내림
3. FlexSim을 통해 강화학습을 사용하고자 한다면, 모델을 훈련시키는 놀이터 정도로 생각해달라.
음....
시뮬레이션을 강화학습 한다는 것은, 결국 AI를 시뮬레이션 한다는 것인가? 단지 활용도는 그 뿐인건가
즉, 돈되고 실적이 오는 업무는 사실 Optimizer이므로
사실상 flexsim + 강화학습은 여기까지가 맞는 듯 하다.
차라리 외판원 문제 TSP(Traveler Salesperson Problem)으로 연구를 파나가는게 맞다고 본다.
얘를 내가 계속 끌고 갈 일은 없어보인다.
다만 해당 주제로 발표건도 있고, 공부해놓은게 아까워서라도
flexSim과 강화학습 (1) flexSim이란 무엇인가?, 무엇을 할 수 있는가? 10월 12일
flexSim과 강화학습 (2) 강화학습이란 무엇인가? 10월 13일
flexSim과 강화학습 (3) PPO란 무엇인가? 10월 3째주
flexSim과 강화학습 (4) 그래서 결론은 무엇인가? 10월 3쨰주
로 글을 작성해서 기록을 남겨보고자 한다.
Job Shop / optimization schduling 이란것도 다뤄봐야 할텐데...
다시 한 번 느낀다. 어렵기만 한 것은 회사원 실적에 최악이다.============================================================
출처 :
플렉심 커뮤니티 :
https://answers.flexsim.com/articles/112703/reinforcement-learning-using-previous-versions.html
'CS > ML&DL' 카테고리의 다른 글
[강화학습] PPO 알고리즘 (1) (미완) (0) 2022.10.19 [pandas] Multiindex의drop 관련 이슈 unhashable type : 'Series' (0) 2022.07.07 [Predict_Future_Sales] 관련 (0) 2022.06.30 [kaggle] Bike_sharing_demand (0) 2022.06.29 [트랜스포머] Vanilla Transformer 관련 (0) 2022.06.13